")

 https://ish-world.com/wp-content/uploads/2024/09/Establishment-of-World-Adherence-Day-scaled.jpg
1707
2560
Helen Horsfield
http://ish-world.com/wp-content/uploads/2021/01/ISH-Logo-full-name-1000x354.jpg
Helen Horsfield2024-09-26 16:49:082024-09-26 16:49:08ISH announces establishment of World Adherence Day
https://ish-world.com/wp-content/uploads/2024/09/Establishment-of-World-Adherence-Day-scaled.jpg
1707
2560
Helen Horsfield
http://ish-world.com/wp-content/uploads/2021/01/ISH-Logo-full-name-1000x354.jpg
Helen Horsfield2024-09-26 16:49:082024-09-26 16:49:08ISH announces establishment of World Adherence DayThe ISH is positively committed to opposing discrimination against people on the grounds of gender, race, colour, nationality, religion, marital status, sexual orientation, class, age, disability, having dependants, HIV status or perceived lifestyle.
Our latest tweets
Follow us @ISHBP to keep up to date with the latest offers and news
HEARTS in the Americas is a large regional adaptation of the @WHO Global HEARTS initiative that is supported by @pahowho.
What can be learned from the initiative?
A lot!
Read article by @deanp_BP in the latest edition of #Hypertension News:
📝https://ish-world.com/wp-content/uploads/2024/07/ISH-Hypertension-News-July-2024_Learning-from-HEARTS-in-the-Americas.pdf
We invite you to join us for our October webinar! Register here: https://tinyurl.com/mr4x6u6x
If you attended @ish_2024 @ISHBP in Cartagena, don't miss this funding opportunity! Check this video and link for more information ⬇️⬇️ Deadline is approaching soon!!
@Dr_NChapman
🎥New video: The ISH Capacity Building Network is pleased to announce the 2024 ISH Collaboration Exchange Scholarship valued at $5,000 USD.
Watch @mari_br_montrea ask @Dr_NChapman how the Scholarship works:
https://www.youtube.com/watch?v=5V5DLSedAX4
https://ish-world.com/wp-content/uploads/2024/09/Establishment-of-World-Adherence-Day-scaled.jpg
1707
2560
Helen Horsfield
http://ish-world.com/wp-content/uploads/2021/01/ISH-Logo-full-name-1000x354.jpg
Helen Horsfield2024-09-26 16:49:082024-09-26 16:49:08ISH announces establishment of World Adherence Day https://ish-world.com/wp-content/uploads/2024/09/ISH-New-Counci-lMembers-2024-images.jpg
720
1280
Helen Horsfield
http://ish-world.com/wp-content/uploads/2021/01/ISH-Logo-full-name-1000x354.jpg
Helen Horsfield2024-09-21 23:29:412024-09-26 16:38:25Introducing ISH 2024 New Council Members
https://ish-world.com/wp-content/uploads/2024/09/ISH-New-Counci-lMembers-2024-images.jpg
720
1280
Helen Horsfield
http://ish-world.com/wp-content/uploads/2021/01/ISH-Logo-full-name-1000x354.jpg
Helen Horsfield2024-09-21 23:29:412024-09-26 16:38:25Introducing ISH 2024 New Council Members https://ish-world.com/wp-content/uploads/2024/09/2024-award-winners.jpg
1080
1920
Helen Horsfield
http://ish-world.com/wp-content/uploads/2021/01/ISH-Logo-full-name-1000x354.jpg
Helen Horsfield2024-09-12 22:41:472024-10-04 16:34:42ISH 2024 Award Winners
https://ish-world.com/wp-content/uploads/2024/09/2024-award-winners.jpg
1080
1920
Helen Horsfield
http://ish-world.com/wp-content/uploads/2021/01/ISH-Logo-full-name-1000x354.jpg
Helen Horsfield2024-09-12 22:41:472024-10-04 16:34:42ISH 2024 Award Winners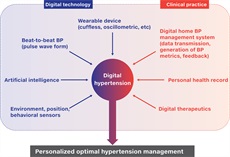 https://ish-world.com/wp-content/uploads/2024/09/Image-for-Kazu-position-paper_Sept-24.jpg
157
230
ISH Secretariat
http://ish-world.com/wp-content/uploads/2021/01/ISH-Logo-full-name-1000x354.jpg
ISH Secretariat2024-09-09 08:51:512024-09-27 11:41:39New blood pressure devices have potential but need proper validation – new ISH position paper
https://ish-world.com/wp-content/uploads/2024/09/Image-for-Kazu-position-paper_Sept-24.jpg
157
230
ISH Secretariat
http://ish-world.com/wp-content/uploads/2021/01/ISH-Logo-full-name-1000x354.jpg
ISH Secretariat2024-09-09 08:51:512024-09-27 11:41:39New blood pressure devices have potential but need proper validation – new ISH position paper https://ish-world.com/wp-content/uploads/2024/05/Dubai-May-2024-e-Bulletin-image.jpeg
374
1128
Helen Horsfield
http://ish-world.com/wp-content/uploads/2021/01/ISH-Logo-full-name-1000x354.jpg
Helen Horsfield2024-05-22 11:36:282024-09-05 15:53:02Venue for ISH 2026 Scientific Meeting announced
https://ish-world.com/wp-content/uploads/2024/05/Dubai-May-2024-e-Bulletin-image.jpeg
374
1128
Helen Horsfield
http://ish-world.com/wp-content/uploads/2021/01/ISH-Logo-full-name-1000x354.jpg
Helen Horsfield2024-05-22 11:36:282024-09-05 15:53:02Venue for ISH 2026 Scientific Meeting announced https://ish-world.com/wp-content/uploads/2024/04/Join-the-ISH-for-free-website-graphic.jpg
405
720
Helen Horsfield
http://ish-world.com/wp-content/uploads/2021/01/ISH-Logo-full-name-1000x354.jpg
Helen Horsfield2024-04-09 23:00:402024-04-10 10:42:46Join the ISH for free
https://ish-world.com/wp-content/uploads/2024/04/Join-the-ISH-for-free-website-graphic.jpg
405
720
Helen Horsfield
http://ish-world.com/wp-content/uploads/2021/01/ISH-Logo-full-name-1000x354.jpg
Helen Horsfield2024-04-09 23:00:402024-04-10 10:42:46Join the ISH for free http://ish-world.com/wp-content/uploads/2021/01/ISH-Logo-full-name-1000x354.jpg
0
0
Helen Horsfield
http://ish-world.com/wp-content/uploads/2021/01/ISH-Logo-full-name-1000x354.jpg
Helen Horsfield2024-04-09 22:44:042024-04-30 10:32:20ISH Lifestyle Position Paper: New directions in management of high blood pressure
https://ish-world.com/wp-content/uploads/2024/03/Thai-Hypertension-Society-March-2203-Abbott-ISH-endorsed-event.jpg
1773
2364
Helen Horsfield
http://ish-world.com/wp-content/uploads/2021/01/ISH-Logo-full-name-1000x354.jpg
Helen Horsfield2024-03-19 16:27:202024-03-20 00:02:39Initiative endorsed by the ISH launched in Thailand to improve hypertension care
http://ish-world.com/wp-content/uploads/2021/01/ISH-Logo-full-name-1000x354.jpg
0
0
Helen Horsfield
http://ish-world.com/wp-content/uploads/2021/01/ISH-Logo-full-name-1000x354.jpg
Helen Horsfield2024-04-09 22:44:042024-04-30 10:32:20ISH Lifestyle Position Paper: New directions in management of high blood pressure
https://ish-world.com/wp-content/uploads/2024/03/Thai-Hypertension-Society-March-2203-Abbott-ISH-endorsed-event.jpg
1773
2364
Helen Horsfield
http://ish-world.com/wp-content/uploads/2021/01/ISH-Logo-full-name-1000x354.jpg
Helen Horsfield2024-03-19 16:27:202024-03-20 00:02:39Initiative endorsed by the ISH launched in Thailand to improve hypertension care



© 2023 International Society of Hypertension. All rights reserved. | Terms & Conditions | Privacy | Home | created by eb-webdesign.com